Robot Skill Adaptation via SAC-GMM
Abstract
A core challenge for an autonomous agent acting in the real world is to adapt its repertoire of skills to cope with its noisy perception and dynamics. To scale learning of skills to long-horizon tasks, robots should be able to learn and later refine their skills in a structured manner through trajectories rather than making instantaneous decisions individually at each time step. To this end, we propose the Soft Actor-Critic Gaussian Mixture Model (SAC-GMM), a novel hybrid approach that learns robot skills through a dynamical system and adapts the learned skills in their own trajectory distribution space through interactions with the environment. Our approach combines classical robotics techniques of learning from demonstration with the deep reinforcement learning framework and exploits their complementary nature. We show that our method utilizes sensors solely available during the execution of preliminarily learned skills to extract relevant features that lead to faster skill refinement. Extensive evaluations in both simulation and real-world environments demonstrate the effectiveness of our method in refining robot skills by leveraging physical interactions, high-dimensional sensory data, and sparse task completion rewards.
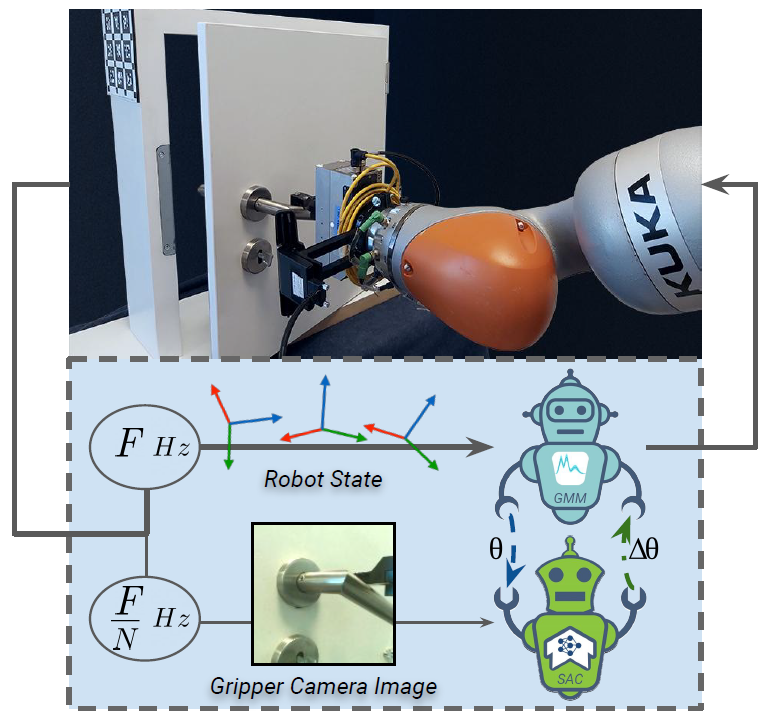
Introduction
Thinking ahead is a hallmark of human intelligence. From early infancy, we form rich primitive object concepts through our physical interactions with the real world and apply this knowledge as an intuitive model of physics for reasoning about physically plausible trajectories and adapting them to suit our purposes.
The most current deep imitation and reinforcement learning paradigms for robot
sensorimotor control are typically trained to make isolated decisions at each time
step of the trajectory. In fact, most of the existing end-to-end high-capacity models
map directly from pixels to actions.
However, although these approaches can capture complex relationships and are flexible to
adapt in face of noisy perception, they require extensive amounts of data, and the trained agent is
typically bound to take a distinct decision at every time step.
The dynamical systems approach for trajectory learning from demonstrations provides a high level of reactivity and robustness against perturbations in the environment. Despite the great success of dynamical systems in affording flexible robotic systems for industry, where a high-precision state of the environment is available, they are still of limited use in more complex real-world robotics scenarios. The main limitations of current dynamical systems in contrast to deep sensorimotor learning methods are their incompetence in handling raw high-dimensional sensory data such as images, and their susceptibility to noise in the perception pipeline.
We advocate for hybrid models in learning robot skills: “Soft Actor-Critic Gaussian Mixture Models”. SAC-GMMs learn and refine robot skills in the real-world and present a hybrid model that combines dynamical systems and deep reinforcement learning in order to leverage their complementary nature. More precisely, SAC-GMMs learn a trajectory-based Gaussian mixture policy of skills from demonstrations and refine it by physical interactions of a soft actor-critic agent with the world. Our hybrid formulation allows the dynamical system to utilize high-dimensional observation spaces and cope with noise in demonstrations and sensory observations while maintaining a reactive and robust trajectory-based policy when interacting with dynamic environments. The method is simple, sample efficient and readily applicable in a variety of robotics scenarios.
Method
Our hybrid approach consists of two phases. In the first, we learn a dynamical system with a Gaussian mixture model from few demonstrations. In the second, we refine this dynamical system with the soft actor-critic algorithm through physical interactions with the world. The key challenges are to learn robot skills from few noisy demonstrations in a trajectory space and to later refine the skills in their own trajectory distribution space in a sparse task completion reward setting.
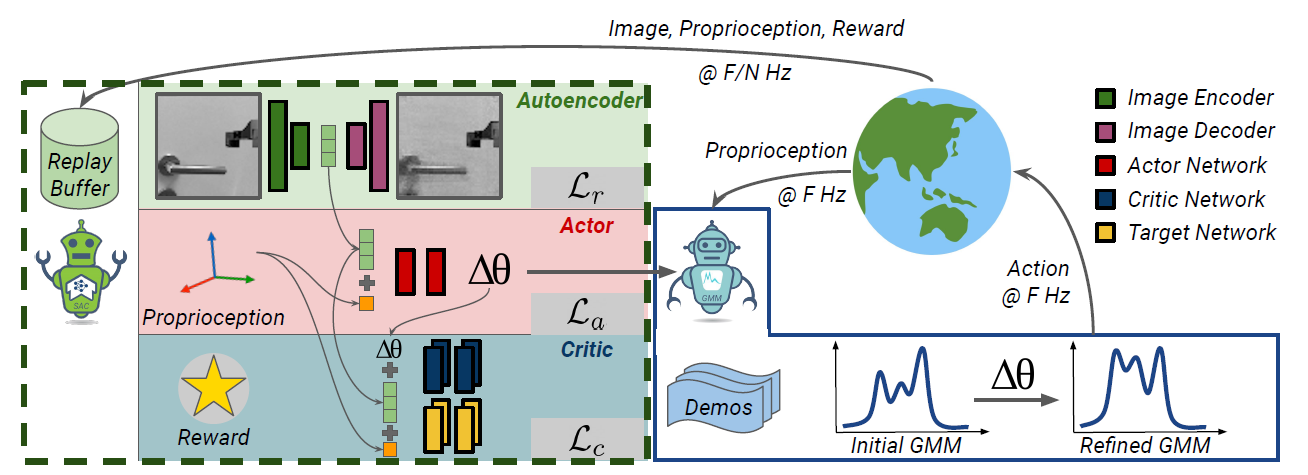
Dynamical Systems: Dynamical systems afford an analytical representation of the robot’s progression over time, particularly we use an autonomous dynamical system that does not explicitly depend on time and employs a first-order ordinary differential equation to map the robot pose to its velocity. From a machine learning perspective, we aim to learn the noise-free estimate of the robot skill model data as a regression problem. The problem can be addressed by using a Gaussian Mixture Model (GMM) with K Gaussian components to represent the joint probability of the robot pose and the corresponding velocity. Maximum-likelihood estimation of the mixture parameters can be carried out iteratively with different optimization techniques such as Expectation-Maximization (EM) algorithms. Finally, we use Gaussian Mixture Regression (GMR) to estimate the most likely velocity given a robot pose.
Soft Actor-Critic: Having learned the robot skill model in the trajectory space, we can now leverage the robot’s interactions with the world to explore and refine the global map of the robot skill. We formulate this refinement as a reinforcement learning problem in which the agent has to modify the learned skill in the trajectory space and has only access to sparse rewards. In RL, the goal is to learn a policy in a partially observable Markov decision process, consisting of an observation space O, a state space S and an action space A. In our skill refinement scenario, the observation space consists of the robot’s sensory measurements such as RGB images, tactile measurements, or depth maps. The state space is continuous and consists of the skill parameters, the robot pose, and latent representations of high-dimensional observations. The action space is also continuous and consists of the desired adaptation in the skill trajectory parameters. Moreover, the environment emits a sparse reward only if the robot executes the skill effectively. The robot has to learn this policy from its interactions with the world, such that it maximizes the expected total reward of the refined skill trajectory. Our particular choice for the reinforcement learning framework to learn the skill refinement policy is the soft actor-critic (SAC) algorithm.
Full model: Our hybrid model learns and refines a robot skill. The GMM agent is fitted on the provided demonstrations and represents a dynamical system, controlling the robot in the trajectory space. After each N interaction of the GMM agent with the world, the SAC agent gets an image, robot state, and reward from the world. The SAC agent optimizes for the robot’s skill success, updates the GMM agent parameters, and refines the robot skill in the trajectory space. While updating GMM parameters, we ensure that mixing weights sum to one and covariance matrices stay positive semi-definite. At the inference time, the same procedure repeats. The GMM agent interacts with the world, and with each N step, the SAC agent receives information about the skill progress and adapts the GMM agent.
Experiments
We evaluate SAC-GMM for learning robot skills in both simulated and real-world environments. The goals of these experiments are to investigate:
- Whether our hybrid model is effective in performing skills in realistic noisy environments
- If exploiting high-dimensional data boosts the dynamical system adaptation
- How refining robot skills in trajectory space compares with alternative exploration policies in terms of accuracy and exploration budget
We evaluate our approach in both simulated and real-world environments. We investigate two robot skills in simulation: Peg Insertion, and Power Lever Sliding. The environments are simulated with PyBullet. The robot receives a success reward whenever the peg is inserted correctly in the hole. We recognize the importance of the sense of touch in fitting a peg smoothly in a hole. Hence, during the skill adaptation phase, we provide the robot with vision-based tactile sensors on both fingers. For the power lever sliding skill, the robot is rewarded whenever it grasps the lever and slides it to the end, such that the light is turned on. For this skill, we provide the robot with static depth perception during the skill refinement to facilitate accurate lever pose estimation. Moreover, to simulate realistic real-world conditions, we also consider noise regarding the detected position of the hole and lever. Namely, in both environments, we add Gaussian noise with a standard deviation of 1 cm in the target pose’s x, y, and z dimensions. For both skills, we collect 20 demonstrations by teleoperating the robot in the simulation.
We compare our skill model against the following models: GMM: This baseline represents the dynamical system that we learn with the provided demonstrations. We use SEDS and LPV-DS frameworks to fit our GMM agents to the demonstrated trajectories. This baseline is not able to explore or leverage high-dimensional observations to refine its performance. SAC: We employ the soft actor-critic agent to explore and learn the skills. We initialize the replay buffer of the SAC agent with the demonstrations of skills. This baseline employs the same SAC structure that we use in SAC-GMM, including the autoencoder for high-dimensional observations and the network architecture. However, this baseline does not have access to a dynamical system, and consequently, does not reason on the trajectory level. Res-GMM: This baseline first learns a GMM agent using the demonstrations and then employs a SAC agent for the exploration. The SAC agent here is very similar to what we use in SAC-GMM, with the difference that it receives information at each time step of the trajectory (instead of each N step), and instead of predicting change in trajectory parameters, it predicts a residual velocity which is summed up with the GMM agent’s predicted velocity. This baseline is inspired by recent approaches in the Residual RL domain. For the quantitative evaluation of skill models, we employ them to perform the skill 10 times at each evaluation step. We report the average accuracy of each skill model over these episodes in our plots.
| Model | Peg Insertion | Lever sliding |
|---|---|---|
| GMM | 20% | 54% |
| SAC | 0% | 0% |
| Res-GMM | 30% | 62% |
| SAC-GMM | 86% | 81% |
For the real-world experiment, we investigate the door opening skill, and place our KUKA iiwa manipulator in front of a miniature door. We put an ArUco marker on the backside of the door. This marker is detected when the robot opens the door and is consequently rewarded. Moreover, to enable our robot to run autonomously without any human intervention, we equip our door with a door closing mechanism. Thus, the door shuts when the robot releases the door handle and starts a new interaction episode. We provide our robot with an Intel SR300 camera mounted on the gripper for an RGB eye-in-hand view during the skill adaptation phase. We use OpenPose to track the human hand and collect 5 human demonstrations of the door opening skill.
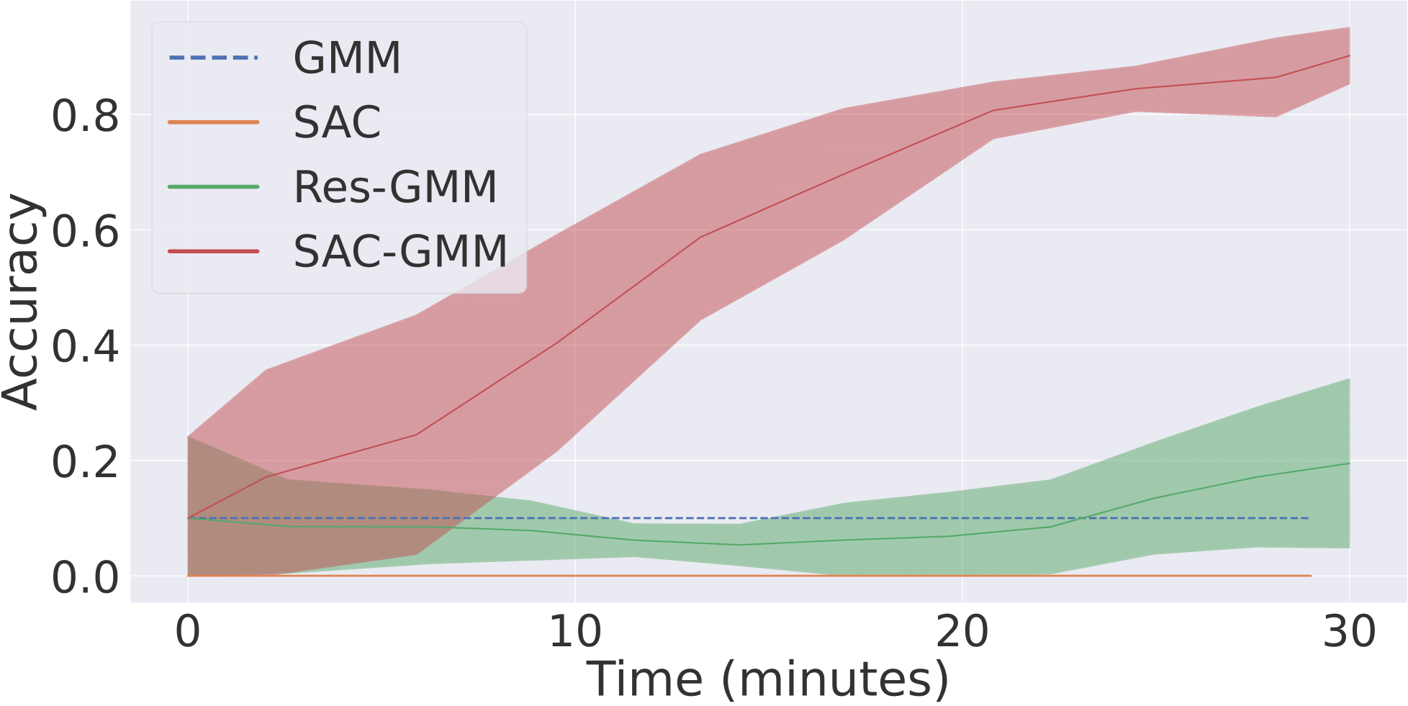
We find that, although the initial dynamical system (the GMM agent fitted on human demonstrations) enables the robot to reach the door handle, the robot misses the proper position to apply its force and can only open the door with a 10% success rate. This failure is due to the robot’s noisy perception and dynamics. Our SACGMM exploits the wrist-mounted camera RGB images and sparse door opening rewards and achieves a 90% success rate after only half an hour of physical interactions (~100 episodes) with the door. The SAC baseline fails to learn the skill and the Res-GMM model performs poorly, as adding residual velocities at each time step results in non-smooth trajectories.
Conclusions
We present SAC-GMMs as a new framework for learning robot skills. This hybrid model leverages reinforcement learning to refine robot skills represented via dynamical systems in their trajectory distribution space and exploits the natural synergy between data-driven and analytical frameworks. Extensive experiments carried out in both simulation and realworld settings, demonstrate that our proposed skill model:
- Learns to refine robot skills through physical interactions in realistic noisy environments
- Exploits high-dimensional sensory inputs available during skill refinement to cope better with noise
- Performs robot skills significantly better than comparable alternatives considering the performance accuracy and exploration costs
Publications
Robot Skill Adaptation via Soft Actor-Critic Gaussian Mixture Models Iman Nematollahi*, Erick Rosete-Beas*, Adrian Röfer, Tim Welschehold, Abhinav Valada, Wolfram Burgard arxiv Pdf
BibTeX citation
@article{Nematollahi2022,
title = {Robot Skill Adaptation via Soft Actor-Critic Gaussian Mixture Models},
author = {Nematollahi, Iman and Rosete-Beas, Erick and Roefer, Adrian and Welschehold, Tim
and Valada, Abhinav and Burgard, Wolfram},
journal = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2022}
}





